
Provenance
A survival toolkit for an AI dominant information landscape
I’ve encountered a few sobering moments in the comment section lately. Not the moments where I realize no one else has noticed what I deem to be obviously AI-generated content. But the ones where I’m made aware I’ve been deceived, only through help from commenters more vigilant than I. The physical senses were never perfect arbiters of authenticity online, but that gap is widening at an accelerating rate. The unfortunate truth is your grandma, someone’s teen nephew, and I are increasingly likely to be deceived as AI sharpens its understanding of reality.
Unless, we follow a path that leads to an ecosystem-level adoption of provenance.
I’m sure others have no trouble forecasting the potential harms, but let’s touch base on some dangers first.
A spectrum of harms: personal to societal
New-age catfishing
Who said AI users can’t be creative? Men are flooding TikTok, X, and Lord help them, Facebook with thirst traps of themselves posing as Gen Z women. Many grifters funnel the captured audience from these free, maximally engaging platforms over to Discord and Telegram where “premium” content is served to paying customers. I’ve seen “How to” guides going around on X to streamline this process. It’s a crude yet effective demonstration of the deception enabled by photorealistic generation.
Weaponizing (lazy) curiosity
Topical research routinely circulates beyond academia and onto mainstream platforms, informing the interested public of public matters. An engaged citizenry helps a democracy function, but a new attack gains appeal as science becomes increasingly politicized. The image below contains fictitious data depicting that increased water intake remedies Alzheimer’s disease. This was fabricated with a single prompt. The dense nature of research papers leads readers to visual aids for digestibility. This tendency lends itself to exploitation for those interested in quick takeaways, such as myself. The authority of believable microscopy imaging doesn’t help. Attackers of this kind would sidestep journals and peer-review in favor of publishing straight to social media. Note, this is a speculative future harm for now but precaution here is sensible.


Coordinated campaigns
Adversarial state actors are using new-age deepfakes to create fake but plausible people. North Korea has been carrying out an IT worker infiltration conspiracy into Fortune 500 companies for years now, but advancements in generative AI allow new scale for such attacks. The number of companies that hired these operatives increased 220% within one year, amounting to 320 companies in that period alone. Once infiltrated, these operatives conduct revenue-generating activity on behalf of the regime, exfiltrate sensitive data, and in some instances have held companies hostage with their own data until ransom demands were met. The fraudulent scheme uses AI to forge identities, stream real-time deepfakes, and manage day-to-day work once hired.
Potential destabilizing forces
A report from the IPIE (International Panel on the Information Environment) found widespread use of gen-AI in election interference during the global 2024 election cycle, though its impacts on election outcomes remain inconclusive.
Since the last election cycle, we’ve transitioned from surreal and often absurd image outputs to renderings nearly indistinguishable from reality. When you play out the trajectory of model capabilities, peddling a single fabricated image on the internet is the rudimentary case. Cohesive, longer-format video incorporating both convincing dialogue and ambient audio to depict candid moments will define the next generation of deepfakes.
Compounding this threat, a phenomenon coined as the Liar’s Dividend emerges. As misinformation erodes societal trust, public figures acquire a basis for denouncing real media as fake if they deem it harmful to their reputation. This plausible deniability grows stronger as mistrust intensifies.
Promise of C2PA: Content Credentials
In a comically red-handed moment, an investigative journalist captures a video of a back-channel deal between a regulator and an industry counterpart. The video circulates on Twitter overnight but by morning the two parties publish a statement invoking the Liar’s Dividend.
How can the journalist prove to others what they witnessed firsthand?
Data about data
Metadata is data about the underlying data or object itself.
There is already established protocol in secure web browsing and software distribution that uses metadata and cryptographic techniques to verify that the party or object is who or what they say they are.
We’ll apply this directly to our scenario above to flesh out key technical details so we can understand ourselves how the trust signals emerge.
Imagine the device used to capture the video is the iPhone 20. The goal is to make any tampering evident as the video propagates across the internet. We can accomplish this through cryptographic signatures.
This hypothetical phone contains a hardware enclave¹, an isolated component of the phone chip where private keys are safeguarded from the rest of the system, even if the main operating system becomes compromised. This isolation is at the hardware level and the keys generated by the enclave are rooted in physical entropy, making them infeasible to guess.
A private key is what produces a cryptographic signature, a public key is used to verify the signature. Public keys are freely shared to anyone who needs them. The pair shares a fixed mathematical relationship. Given some content and the signature over it, the public key can determine if that signature was produced by the paired private key.
Shortly after the moment of the journalist’s video capture, the iPhone begins constructing a metadata file adhering to an open, standard specification.
In the most promising provenance standard of today, this file is known as a C2PA (Coalition for Content Provenance and Authenticity) Manifest. Key items include:
Assertions
A claim which is the aggregate of those assertions
A cryptographic signature over that claim
An assertion is a statement about the digital content. In our example the assertions we would likely see are:
Details about the capturing device ( iPhone 20 )
Date, time, and location of capture ( any self-identifying disclosures are controlled by the user )
Actions performed on the content such as “created”, “cropped”, “compressed”...
And critical to the trust signal, a hard binding to the content
A hard binding is a hash of the content, a fingerprint derived deterministically from the raw bytes of the video. If you feed the same video in you get the same fingerprint out every time. Change even a single byte of input and the hash changes entirely. This hard binding, together with the other assertions, is bundled into the asset’s claim, which is then signed using the private key from the phone’s secure enclave.
So, the claim + signature are used by downstream parties to ensure the content has not been tampered with:
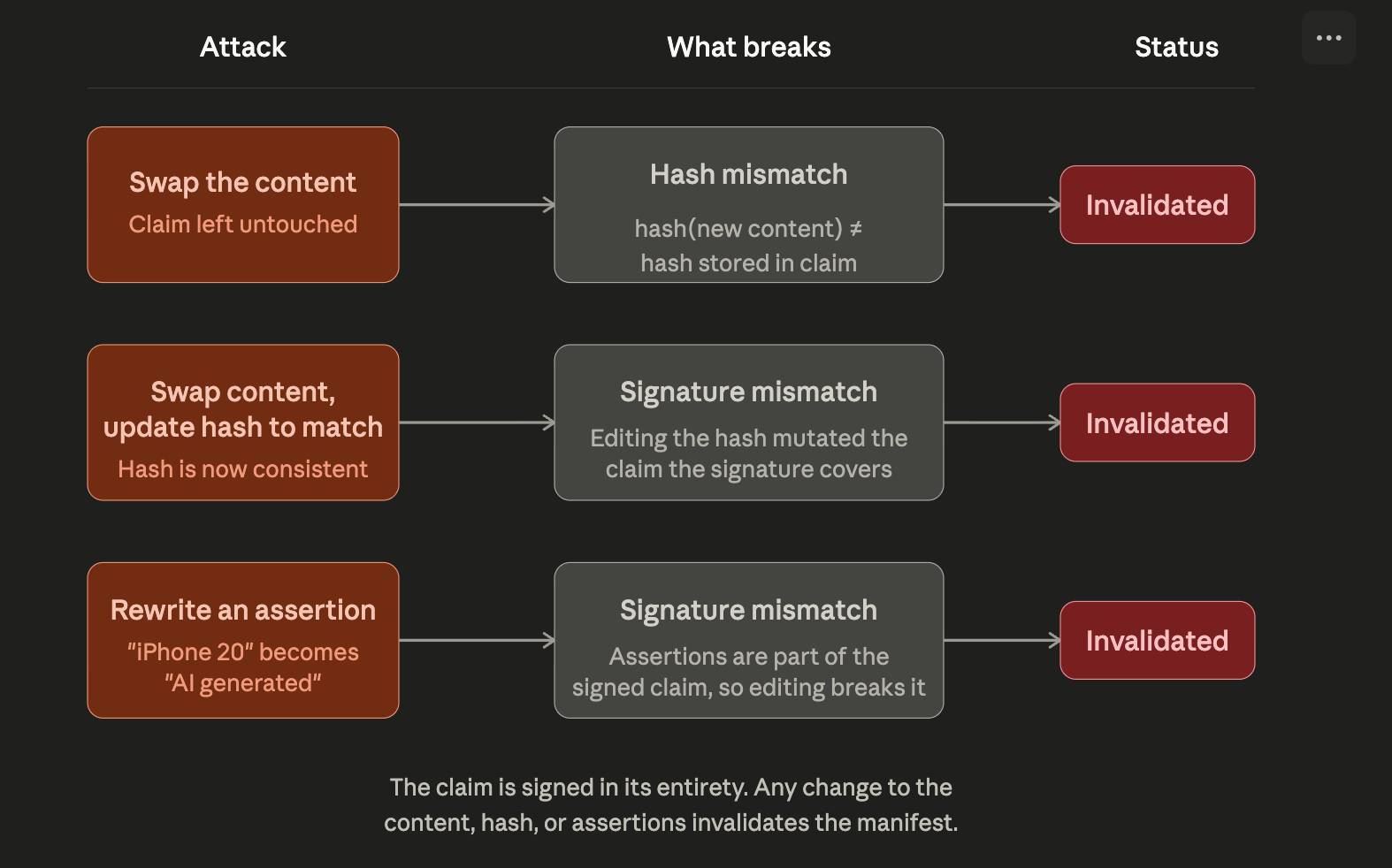
Once the manifest is assembled, the journalist uploads the video across social media platforms to garner attention. During upload, the C2PA manifest is attached alongside the video content and, key to this scenario, the media platforms preserve the metadata.
Say this video gains traction on Twitter. Some users readily believe the video, others are inherently skeptical of online content these days, and others are persuaded this is a smear campaign because the subjects of the video happen to be reputable figures who are publicly denying its legitimacy.
Now provenance demonstrates its public significance. Twitter reads and verifies the integrity of the claim. Twitter then surfaces to the user the validity of the provenance data and its key assertions.
Users can see this video indeed originated from an optical sensor and that no alterations have been made, all of which are attested through Apple’s public keys.
There is debate on how to surface this information to users. I’m no UI expert, but we should expect the folks at Meta and the like will know how to best present this information, if incentivized to.
2 Chainz: claims and certs
In our simplified example, there was only one signing identity, Apple. In most cases there’ll actually be several. A capture device manufacturer, a video editing app, maybe a generative AI model, with each declaring their modifications on the trace represented by the manifest.
Every identity present in the manifest is subject to these two questions: “What are they claiming” and “Can I trust them?”.
C2PA answers these questions utilizing two distinct chains.
We already saw what claims are and how they’re used. In the case of multiple, successive changes to a piece of content, the accompanying manifest will contain a chain of claims², each claim verifiably attributable to the signer.
To answer the question of trust, a chain of certificates is used. Each identity’s certificate is endorsed by a higher authority, and the higher authority is endorsed by yet a higher one, until the chain terminates at a root authority that platforms already trust. If any link in the chain is broken the trust signal dissipates.
To unpack, consider a more frivolous scenario where a casual weightlifter prepares a post to Instagram claiming a new personal record.
We fork into two paths from here:
“lightweight bro”
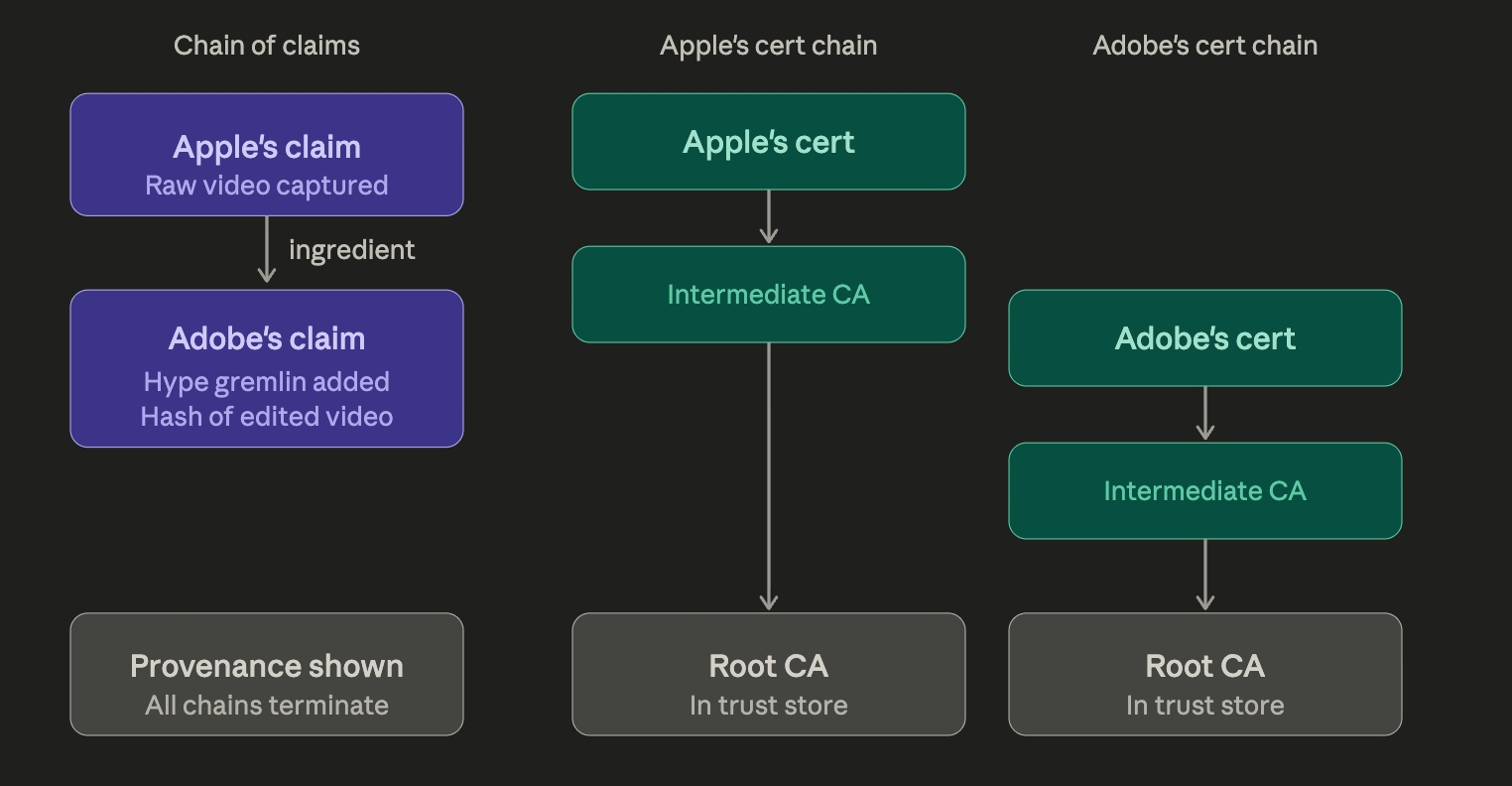
The lifter trims the video, and then uses their preferred editing app, Adobe, to add some generative AI effects. There are many sensible effects they might utilize but we’ll go with a hype gremlin placed in the room’s corner that yells during the crux of the movement. The manifest on the accompanying post shows a hierarchy of claims:
The first created and signed by Apple, similar to what we saw earlier.
The second is a new claim, created and signed by Adobe, containing the assertions: “Hype gremlin added”, a hash of the newly edited video, and an ingredient. An ingredient is a reference to an earlier claim. The ingredient here being Apple’s claim of the raw video from which the edited one was derived.
Instagram would read and verify both claims using the respective public keys finding each signature to be mathematically valid.
Additionally, Instagram checks if Apple’s and Adobe’s certificates chain to a trusted authority.
A certificate, also implicitly present in the journalist example, is a document issued by a certificate authority (CA) to a claim maker, like Apple or Adobe, that endorses their compliance and holds their public key.
Instagram climbs link by link up the certificate chains of both Apple and Adobe and for each finds valid connections directly to a root CA present in its trust store.
Stolen valor
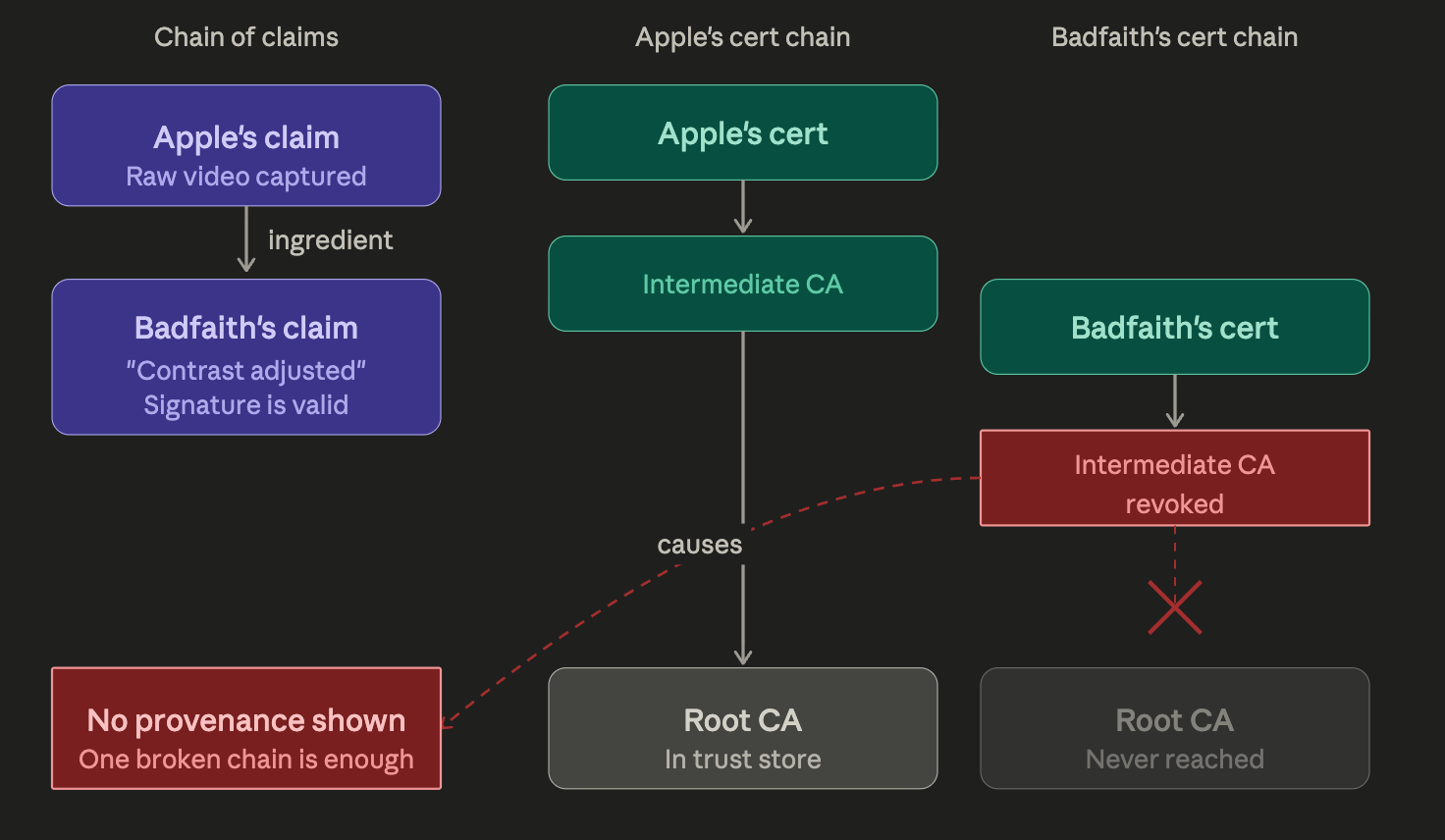
In an alternate timeline, the lifter uses a video generation model, from the indie AI provider Badfaith LLC, to inconspicuously add a pair of 25s to each side of the barbell. Badfaith attaches a new claim with the deceptive assertion “contrast adjusted”.
Instagram reads the manifest with the new claim and begins the verification process. It verifies the signed claim is valid, implying the content hasn’t been tampered with since.
Again, Instagram begins the climb up Badfaith’s certificate chain to see if someone they trust endorses them. However, a broken link is found. It turns out the chain’s highest authority recently revoked a certificate from one of the intermediate ones after it was caught issuing fraudulent certs to shady actors.
As a result, viewers of the weightlifting video do not see validated provenance as part of the post.
Judgment not included
Provenance is intended as an additional basis for exercising prudence. It doesn’t attest to the meaning conveyed by the content. An out-of-context clip is still just that. A photo op is still an arranged staging. Ambiguous images are still subject to interpretation. All these media pieces may have verifiable provenance but there is still a degree of judgment required about their meaning. On the other hand, if a piece of digital media is outright dubious, you know it when you see it. No metadata needed.
How it’s presented is also critical to how the public makes use of it. Platforms must not display a green shield on top of verified provenance or place a red “X” against its absence. A neutral, informative UI component about the digital item’s origin helps ensure users don’t conflate provenance signals as evidence for truthfulness.
Credibility of a given entity is associated with things like track record and reputation. The thing about reputation is that once you harm it, it’s a long journey to build it back. But when it comes to the online security community and governing provenance bodies, reinstating a certificate revoked for fraudulent behavior isn’t something that should be expected. Trust in this space is an all-or-nothing social contract.
A revocation due to a breach of provenance compliance could be devastating for a business. Apple is a neutral player and has no reasonable incentive to sign fraudulent claims. It’s in its best financial interest to stay neutral and play its part as a hardware-level claim maker. X, Instagram, TikTok, Reddit and other media-sharing platforms under a motivating policy framework would follow suit.
Cat and mouse
Readers familiar with the AI information landscape might be wondering “What about AI detectors?”. The framework we detailed above assumes that provenance data is preserved throughout the lifetime of the digital asset. Detectors are used for cases where only pixel-level information exists.
The reality is that these tools exist inside a skewed arms-race against their favor. An attacker given a little know-how can utilize adversarial or open-source models to neutralize or completely evade these detection measures.
Online AI content detectors exist today and we can categorize them into two forms. We’ll start with the more untenable of the two.
Statistical forensic detectors
Forensic detectors try to detect AI output in a provider-agnostic manner. They attempt to interpret statistical signals and artifacts typically associated with general AI output. They assign a confidence score based on the interpreted signal as to the probability the content is AI generated.
Statistical forensic detectors are much weaker and are generally more unreliable than their watermark counterparts due to the varied means by which AI generates output. They are models themselves that require their training distribution to contain adequate amounts of the specific model outputs they are attempting to detect.
This is a broad goal and makes detection a constant moving target with the advantage belonging to the attacker as they only need one generative model that lies outside the training distribution of the detector while the detector needs to work reliably against most models.
Watermark detectors
Google DeepMind takes the output from its generation models and uses a separate network to embed a holographic watermark into the pixels. It distributes the signal across the entire frame so it survives actions such as cropping and compression.
Meta’s approach trains its generation models such that the model weights encode the watermark signal inherently into its output.
Both providers, among others, attempt to robustly embed invisible, identifying information into their generated digital media so that their corresponding detectors still work against long-lived content.
Watermark detection requires the detector to know ahead of time what the identifying signals look like. Google’s detector outputs an answer to the question “Is this a Gemini output?”. Meta and others do the same respectively.
There are two ways to muddy these signals:
Guided removal - An attacker has some knowledge of the watermark decoder workings and optimizes a model to take target content as input and continuously drive the watermark signal to zero.
Unguided regeneration - Arguably a cheaper, less sophisticated yet more effective attack. An attacker uses the media item as input to a diffusion model, which by nature iteratively noises and denoises input, allowing for a re-synthesis of the original item while preserving the original human-perceptible content and effectively removing the watermark signal.
Realism threshold
If I’m an attacker, the only reason I would use a generative AI model from compliant, frontier labs is to obtain output indistinguishable from something that was captured on a real camera. As the frontier models advance from one reality modeling capability to the next, open-source models follow behind by a several month gap. At some point, probably in a couple of years, longer-format and realtime deepfakes will be imperceptible to all but the most trained eyes. Once we reach that moment, there is no reason to use an AI model from a provider that embeds watermarked content. I would simply use the accessible and non-compliant open-source models whose output would reliably avoid statistical forensics.
That said, research in detection technology should continue. The scope of impact disinformation poses warrants it. However, it shouldn’t be our primary strategy in determining provenance of information, but can act as a useful complement in certain contexts.
When signed claims become the norm
Detectors interrogate digital artifacts to compute a probability, C2PA cryptographically attributes provenance claims to trusted identities.
As the information ecosystem steadily produces, preserves, verifies, and surfaces C2PA manifests, the proportion of signed vs unsigned content the public sees increases. Good-faith and neutral actors producing and posting digital content in a largely compliant ecosystem mean provenance information will be present for both sensor-captured data and AI generated data.
As we raise the statistical baseline of signed content, unsigned content trends towards becoming anomalous and a heuristic signal of illegitimacy.
The burden of proof should shift such that those who post content and state it as a matter of fact require a signed provenance chain for some degree of credibility. We progressed culturally years ago to avoid outright belief of what you see online, we’re still working on developing that muscle.

This discipline must only grow stronger as we move into an increasingly AI dominant information landscape.
It is burdensome to navigate through life without taking anything at face value. You constantly intake new information and, when it doesn’t fit nicely, you arduously reconcile your world model.
Thankfully, not everything requires this effort. For the things that do, for digital media we deem consequential, provenance lessens the cognitive friction and adds necessary signal.
California( codifi )cation
In 2024, California signed the California AI Transparency Act. This act by itself was only one piece of the many components required in the provenance pipeline.
More than a year later, the bill was expanded in scope by AB 853.
Effective dates:
August 2, 2026 - Require generative AI systems with over 1,000,000 users to provide standardized provenance data for image, video, and audio outputs.
January 1, 2027 - Require large online media platforms to surface and preserve provenance data attached to content.
January 1, 2028 - Require capture device manufacturers to provide opt-in provenance disclosures including device manufacturer information.
This is a real milestone but it is only policy for one state, and it has yet to be implemented.
Criticisms
Two chief criticisms stand out when it comes to C2PA’s content credentials: privacy and technical coverage.
Anonymity
Self-identifying disclosures were only mentioned in passing earlier. But in fact, anonymity concerns were one of the bases for political lobbying against previous provenance bills.
The obvious answer is to mandate the assertions made by claim makers to be anonymous by default. Within the C2PA conformance program, any device manufacturer or claim attacher that includes personally identifying information (PII) is non-compliant and cannot enter the Trust List. The program enforces this further by revoking certification from implementers that later override the opt-in default. That is already where the C2PA governing body stands today.
The many arguments concerning speech chilling, harassment, authoritarian targeting, and anything else downstream of reduced anonymity are justified but don’t hold weight if the overwhelming majority of provenance data generated doesn’t include PII, which appears to be the most likely scenario.
I’m not aware of any proposed or enacted policy that financially penalizes claim generators who by default include PII but this gap is a substantive one and would make a sensible next discussion for privacy advocates. Closely related, there is existing adjacent law (CCPA/CPRA) that dictates how businesses must handle personal information and it may reach into the realm of content credentials, acting as an additional check on broad PII disclosure in provenance data.
Analog Gap
What if you just take a picture of a physical picture? If staged well enough, one might get a printed AI generated image to circulate online by hijacking the trust signals afforded by a valid provenance assertion like “taken on iPhone 20”.
There isn’t a straightforward bridge over this gap. At this moment in time, I think the most realistic path is further enriching assertions made in content credentials. However, this comes at the cost to the complexity of provenance information, thereby limiting its broad usefulness.
These enriched signals would be derived from two technical techniques:
Depth binders - The most common consumer camera device type is a phone. Most of these phones feature multiple cameras and some include technologies such as LiDAR. These sensors enable detection of flat imagery that does not carry the same depth information depicted by the scene they are capturing.
Classifiers - Purpose-built forensic analysis algorithms and ML models available today for this problem could be employed directly on capture devices and the cloud platforms these images circulate on.
Together these would provide coverage for the most common uploads. If a sophisticated attacker sidesteps the depth binders at capture time, the classifiers would come into play further into the content lifecycle. The first wave of impact is the attacker’s target, because as it garners more eyeballs, the more likely it’ll be sniffed out.
There are both merits and tradeoffs against these partial solutions. This is exactly where more layered defenses around content credentials could help so that they don’t have to stand alone.
I touched on the infeasibility of always carrying a deep online skepticism earlier. In a world where we don’t believe anything, where people can’t extend credibility to something, an unsustainable civic condition arises. But, this is a different position than not believing everything. The epistemic support provided by structural provenance gives us a degree of confidence to actually engage online. The equilibrium provided by a mature provenance ecosystem in the long run beats the equilibrium that is settled into by an entirely default-disbelief society with little signal to grab onto.
Didn’t we just get to the Information Age?
We’ve been inscribing our thoughts onto durable formats for some time now. Paper, and then the printing press, accelerated memetic transmission but it was the nascent transistor of the 20th century that enabled the latest step change. Personal computing and online search gave additional function to the internet, yet it was the recent pull of instant social interaction that drove mass adoption of it. We’re still getting a grip on this instant, broadcast-able communication form. It was already hurting us before the advent of AI. We’ve had less than one generation’s worth of time to adapt to this seminal technology. This new form, and sheer scale of, interactivity has coalesced into a sort of emergent, online collective consciousness. But this thing does not exhibit the cohesion of some sci-fi hivemind. Individuals, sure, possess some degree of internal contradiction, but they pale in comparison to the entropy of the internet. Some tension, of course is needed, progress as we know it wouldn’t exist without the friction of seemingly opposing ideas from diverse perspectives. But with newly accessible, cheap, convincing synthetic generation, the balance of order versus chaos in the internet may tip further to the latter.
The pervasive sabotage present in the information ecosystem that is our internet is a societal-level destabilizer of our time.
Information literacy becomes a survival skill with provenance on the toolbelt.
¹ Newer iPhones already contain a hardware enclave, but aren’t currently being used for provenance signing.
² To be precise, it’s a chain of manifests and not one of claims. Each C2PA manifest contains a signed claim and is a self-contained unit of provenance.
fascinating analysis!